Questões de Concurso
Filtrar
67 Questões de concurso encontradas
Página 11 de 14
Questões por página:
Na instalação de um sistema de suporte e manutenção de TI baseado em Operações de TI assistidas por Inteligência Artificial (AIOps), um dos componentes do sistema está utilizando algoritmos que permitem correlacionar dados não estruturados, eliminar ruídos, alertar sobre anormalidades, identificar causas prováveis e estabelecer linhas de base.
Na terminologia de componentes de AIOps, esse tipo de algoritmo é um algoritmo de
Uma empresa usará a tecnologia de Inteligência Artificial para Operações (AIOps) para prever problemas potenciais, como falhas de servidores ou congestionamentos de rede, permitindo que suas equipes de TI atuem proativamente.
No momento, o sistema está trabalhando na fase de Observação que é identificada como sendo a fase na qual a AIOps
Considerando-se esse contexto, qual é a característica da técnica RAG?
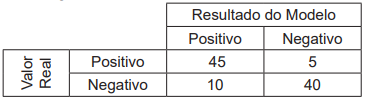
Considerando-se esse contexto, quais são, respectivamente, os valores aproximados, em 2 casas decimais, da precisão (precision) e da revocação (recall) obtidos pelo modelo?
Considere as seguintes afirmativas com relação à mitigação dos riscos identificados:
I - adotar uma abordagem de fairness-aware learning para corrigir potenciais vieses no modelo, garantindo que as recomendações sejam justas para todos os grupos de usuários.
II - implementar métodos de robustness testing para simular ataques adversariais e avaliar a resiliência do modelo, e realizar auditorias regulares para identificar e corrigir vieses algorítmicos.
III - implementar técnicas de data augmentation para aumentar a diversidade dos dados de treinamento, reduzindo o risco de viés algorítmico, e adotar uma estratégia de monitoramento contínuo para detectar e mitigar ataques adversariais.
IV - utilizar técnicas de differential privacy durante o treinamento do modelo para proteger dados sensíveis e garantir que as previsões do modelo não revelem informações específicas dos clientes.
Estão corretas as seguintes afirmativas:
