Questões de Concurso
Filtrar
67 Questões de concurso encontradas
Página 6 de 14
Questões por página:
Para essa automação, deve ser utilizada uma aplicação de aprendizado de máquina que
Julgue o próximo item, relativo à avaliação de modelos.
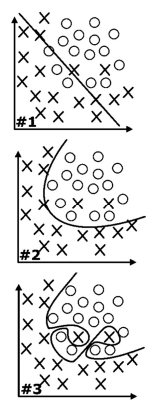
Considere que os três gráficos identificados por #1, #2 e #3 a seguir representem resultados de modelos de classificação em uma base de treinamento com dados de uma agência bancária e que neles a linha separe duas situações: X indicativo de não pagamento de empréstimo e O indicativo de pagamento de empréstimo. Com base nessas informações e nos gráficos apresentados, é correto afirmar que #1 é o modelo mais simples e performático com baixo viés, o modelo #2 tem acurácia média e alto viés e #3 é o modelo ideal, em comparação aos demais, pois tem alto viés e alta acurácia.
Julgue o próximo item, relativo à avaliação de modelos.
A IA generativa é capaz de criar conteúdos novos, como textos, imagens, músicas e vídeos, além de resolver problemas inéditos com base em conhecimentos prévios, permitindo gerar novos artefatos realistas em escala, sem repeti-los.
Julgue o próximo item, relativo à avaliação de modelos.
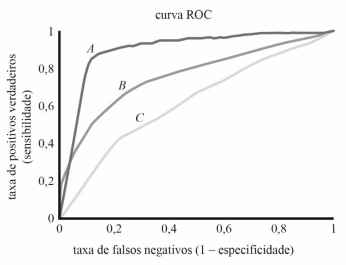
Considere que o gráfico a seguir descreva o resultado de três modelos de regressão logística distintos e que os resultados de AUC para os modelos referentes às curvas A, B e C sejam, respectivamente,0,91,0,77 e 0,59. A partir dessas informações, é correto afirmar que o modelo relativo à curva A é o melhor para classificar corretamente os dados presentes no conjunto de dados utilizado, ainda que o modelo relativo à curva C tenha obtido o menor valor.