60 Questões de concurso encontradas
Página 8 de 12
Questões por página:
- id_processo: Identificador único do processo.
- data_abertura: Data em que o processo foi aberto.
- data_encerramento: Data em que o processo foi encerrado.
A equipe deseja calcular o tempo de tramitação (em dias) de cada processo e inseri-lo em uma nova coluna chamada tempo_tramitacao. Considerando que o arquivo foi carregado em um dataframe chamado dados, o comando R que realiza corretamente esta tarefa é:
Considere o código Python abaixo que utiliza a biblioteca pandas para manipular um conjunto de dados.
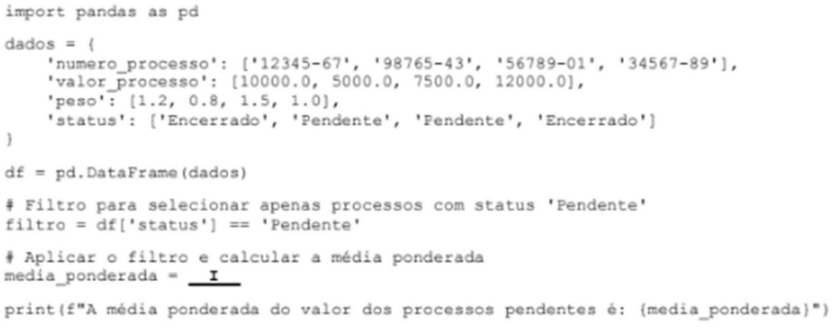
Considerando que o cálculo da média ponderada utiliza a fórmula Média Ponderada= Sí(valorxpeso) / T(peso). e que o código será executado em condições ideais, a lacuna I é corretamente preenchida com
Considere a tabela t_audiencias que armazena informações sobre audiências marcadas.
Considerando que esta tabela está criada e contém valores adequados, em um banco de dados MySQL aberto e funcionando em condições ideais, o comando que seleciona todas as audiências que estão marcadas como “pendente”, cuja data de audiência seja posterior ao dia e hora atuais e que pertençam às varas de trabalho 1,2 0u 3, é:
SELECT * FROM t_audiencias WHERE status = 'Pendente' AND
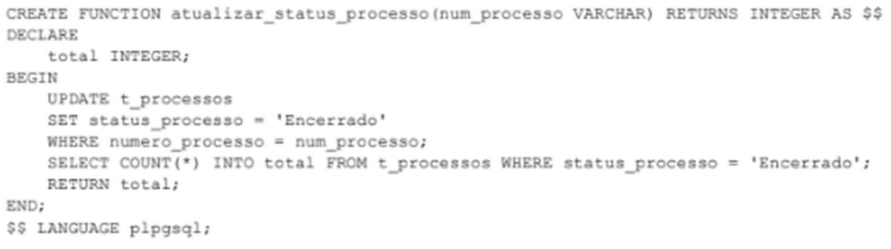
Em condições ideais, esta função seria corretamente chamada utilizando-se o comando:
- id_processo (número único de identificação do processo)
- data_abertura (data em que o processo foi aberto)
- id_vara (identificador da vara do trabalho onde o processo tramita)
- valor_processo (valor monetário associado ao processo)
O comando SQL que lista 0 id_vara, O número total de processos por vara e o valor total dos processos, em ordem decrescente, somente das varas que possuem mais de 100 processos abertos antes de 1º de janeiro de 2020, é:
